Coding Tutorials¶
Simple Ebay scraper (Ruby)¶
Let’s create an ebay scraper from scratch. In this tutorial, we will go step by step in creating a scraper that scrapes an ebay listing page, and loop through each of the pages to extract some related information from it. You will also get familiarized with the basic usage of developing on the Fetch platform.
If you want to see the the exercise solutions, please refer to the branches in https://github.com/answersengine/ebay-scraper
Exercise 1: Create a base scraper locally¶
In this exercise we will create a base scraper. At minimum a scraper needs a seeder script for it to run. After that we will commit and deploy to Fetch.
Let’s create an empty directory first, and name it ‘ebay-scraper’
$ mkdir ebay-scraper
Next let’s go into the directory and initialize it as a Git repository
$ cd ebay-scraper
$ git init .
Initialized empty Git repository in /Users/workspace/ebay-scraper/.git/
Now, let’s create a seeder script. A seeder script gets run when a scraping job is run. This allows for us to seed the first few pages that will need to be fetched and parsed by Fetch.
Let’s create a seeder directory first, so that we can put any files related to our seeding there. This is a good convention to keep our codes organized
$ mkdir seeder
Next, let’s create a ruby script called seeder.rb in the seeder directory with the following content:
pages << {
page_type: 'listings',
method: "GET",
url: "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682"
}
In the ruby script above, we are basically seeding an Apple iPhone page on ebay, so that Fetch can download the page so that it can be parsed. We are also setting page_type to ‘listings’, this allows Fetch to know which parser script to use to parse the content of this page. More on this on Exercise 3. Note that pages is a reserved variable. It is an array that represents what pages you want to seed, so that it gets fetched.
After you’ve created the seeder.rb file, the seeder directory, should look like this:
$ ls -alth
total 8
-rw-r--r-- 1 johndoe staff 122B 26 Nov 16:16 seeder.rb
drwxr-xr-x 3 johndoe staff 96B 26 Nov 16:15 .
drwxr-xr-x 4 johndoe staff 128B 26 Nov 16:15 ..
Let’s go back to the root directory of the project
$ cd ..
$ ls -alth
total 0
drwxr-xr-x 10 johndoe staff 320B 26 Nov 16:19 .git
drwxr-xr-x 3 johndoe staff 96B 26 Nov 16:15 seeder
drwxr-xr-x 4 johndoe staff 128B 26 Nov 16:15 .
drwxr-xr-x 10 johndoe staff 320B 26 Nov 15:59 ..
Now that we’ve created the seeder script, let’s see if there are any syntax error in it. Luckily for us, by using the answersengine command line interface(cli), we can trial-run a script without actually saving it to Fetch.
From the root of project directory, let’s try the seeder script.
$ answersengine seeder try ebay seeder/seeder.rb
Trying seeder script
=========== Seeding Script Executed ===========
----------- New Pages to Enqueue: -----------
[
{
"page_type": "listings",
"method": "GET",
"url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682"
}
]
If you see the above, it means the trial-run was successful.
Let’s now commit this git repository
$ git add .
$ git commit -m 'created a seeder file'
[master (root-commit) 7632be0] created a seeder file
1 file changed, 5 insertions(+)
create mode 100644 seeder/seeder.rb
Next, let’s push it to a online git repository provider. In this case let’s push this to github. In the example below it is using our git repository, you should push to your own repository.
$ git remote add origin https://github.com/answersengine/ebay-scraper.git
$ git push -u origin master
Counting objects: 4, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (4/4), 382 bytes | 382.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0)
remote:
remote: Create a pull request for 'master' on GitHub by visiting:
remote: https://github.com/answersengine/ebay-scraper/pull/new/master
remote:
To https://github.com/answersengine/ebay-scraper.git
* [new branch] master -> master
Branch 'master' set up to track remote branch 'master' from 'origin'.
Ok, looks like this has successfully pushed.
Let’s now create a config file. A scraper requires a config file so that Fetch understands how to seed, and do other things. Create a config.yaml file in the root project directory with the following content:
seeder:
file: ./seeder/seeder.rb
disabled: false # Optional. Set it to true if you want to disable execution of this file
The config above simply tells Fetch where the seeder file is, so that it can be executed.
Let’s now commit this config file on git, and push it to Github.
$ git add .
$ git commit -m 'add config.yaml file'
[master c32d451] add config.yaml file
1 file changed, 3 insertions(+)
create mode 100644 config.yaml
$ git push origin master
Counting objects: 3, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 383 bytes | 383.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/answersengine/ebay-scraper.git
7632be0..c32d451 master -> master
Congratulations, you’ve successfully created a base scraper that includes a seeder script and a config file. You’ve also pushed this scraper codes to Github.
In the next exercise we’ll learn how to run this scraper on Fetch.
Exercise 2: Run the scraper on Fetch¶
In the last exercise, you’ve learned to create a bare minimum requirement of a scraper. Let’s now run this scraper on Fetch. If you’ve skipped the last exercise, you can see the source code here: https://github.com/answersengine/ebay-scraper/tree/exercise1
Let’s run the code on Fetch now. But before we do that, we need to create the scraper first using the code that was created. You also need the URL to your scraper’s Git repository.
Create the scraper on Fetch and name it ‘ebay.’
$ answersengine scraper create ebay https://github.com/answersengine/ebay-scraper.git
{
"name": "ebay",
"id": 20,
"account_id": 1,
"force_fetch": false,
"freshness_type": "any",
"created_at": "2018-11-26T22:00:43.007755Z",
"git_repository": "https://github.com/answersengine/ebay-scraper.git",
"git_branch": "master",
"deployed_git_repository": null,
"deployed_git_branch": null,
"deployed_commit_hash": null,
"deployed_at": null,
"config": null
}
If you see the above, that means it successfully created the scraper.
Next, we need to deploy from your remote Git repository onto Fetch.
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
"id": 122,
"scraper_id": 20,
"commit_hash": "c32d4513dbe3aa8441fa6b80f3ffcc5d84fb7a03",
"git_repository": "https://github.com/answersengine/ebay-scraper.git",
"git_branch": "master",
"errors": null,
"success": true,
"created_at": "2018-11-26T22:03:09.002231Z",
"config": {
"seeder": {
"file": "./seeder/seeder.rb"
}
}
}
Seems like the deployment was a success, and that there were no errors.
You can also see the deployment history of this scraper as well.
$ answersengine scraper deployment list ebay
[
{
"id": 122,
"scraper_id": 20,
"commit_hash": "c32d4513dbe3aa8441fa6b80f3ffcc5d84fb7a03",
"git_repository": "https://github.com/answersengine/ebay-scraper.git",
"git_branch": "master",
"errors": null,
"success": true,
"created_at": "2018-11-26T22:03:09.002231Z",
"config": {
"seeder": {
"file": "./seeder/seeder.rb"
}
}
}
]
Of course, because there was only one deployment, you only see one here.
Let’s now start the scraper.
$ answersengine scraper start ebay
Starting a scrape job...
{
"id": 70,
"scraper_id": 20,
"created_at": "2018-11-26T22:06:54.399547Z",
"freshness": null,
"force_fetch": false,
"status": "active",
"seeding_at": null,
"seeding_failed_at": null,
"seeded_at": null,
"seeding_try_count": 0,
"seeding_fail_count": 0,
"seeding_error_count": 0,
"worker_count": 1
}
Doing the above will create a new scrape job and run it. Notice that the job status is “active”. This means that the scraper job is currently running.
Let’s give it a minute, and see the stats of the job:
$ answersengine scraper stats ebay
{
"job_id": 70, # Job ID
"pages": 1, # How many pages in the scrape job
"fetched_pages": 1, # Number of fetched pages
"to_fetch": 0, # Pages that needs to be fetched
"fetching_failed": 0, # Pages that failed fetching
"fetched_from_web": 1, # Pages that were fetched from Web
"fetched_from_cache": 0, # Pages that were fetched from the shared Cache
"parsed_pages": 0, # Pages that have been parsed by parsing script
"to_parse": 1, # Pages that needs to be parsed
"parsing_failed": 0, # Pages that failed parsing
"outputs": 0, # Outputs of the scrape
"output_collections": 0, # Output collections
"workers": 1, # How many workers are used in this scrape job
"time_stamp": "2018-11-26T22:09:57.956158Z"
}
From the stats above, we can derive that one page has been seeded, and that one page has been fetched by our scrape job. So this looks Good.
Just to be sure, let’s check the scraper log to see if there are any errors:
$ answersengine scraper log ebay
Seems like there are no errors so far.
You have now successfully ran a scrape job on Fetch
Congratulations, you have completed exercise 2.
To see the codes that was done throughout this exercise, please visit https://github.com/answersengine/ebay-scraper/tree/exercise2
In the next exercise, we’ll learn how to write a parser script so that we can parse the pages that has been enqueued by the seeder.
Exercise 3. Create parser script¶
In this exercise, we’ll learn how to write a parser script so that we can parse the pages that has been fetched, and output it into a collection. If you have not done Exercise 2, please do so first, as this exercise depends on exercise 2.
To continue where we left off, let’s look at the pages that has been enqueued and fetched.
Look at the page list that is in the ebay scraper.
$ answersengine scraper page list ebay
[
{
"gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e", # Global ID
"job_id": 70,
"page_type": "listings",
"method": "GET",
"url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
"effective_url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
"headers": null,
"body": null,
"created_at": "2018-11-26T22:07:49.013537Z",
...
"fetched_at": "2018-11-26T22:08:03.14285Z",
...
}
]
This returns the page that the seeder have enqueued. Also, take note of the GID field www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e GID (Global ID) is a very important concept in Fetch. This represents a unique identifier of that particular page that you’ve enqueued. You can refer to this particular page by referring to this GID.
If you want to see the scraper job’s page in, you can do like so:
$ answersengine scraper page show ebay www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e
{
"gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"job_id": 70,
"page_type": "listings",
"method": "GET",
"url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
"effective_url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
...
You can also take a look at the Global page for this GID. Think of the global page as a shared-cache of metadatas and contents related to pages that all Fetch users have fetched. Globalpage contains many more information about the page than the scraper’s job page. Please refer to the “High Level Concepts” section to learn more.
$ answersengine globalpage show www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e
{
"gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"hostname": "www.ebay.com",
"method": "GET",
"url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
"effective_url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
"headers": null,
"body": null,
...
Now that you’ve seen an information of a global page, let’s look at the actual content that is stored in the cache. Let’s take the same GID and preview the content of that page
$ answersengine globalpage content www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e
Preview content url: "https://fetch.answersengine.com/public/global_pages/preview/ICK7bZUfp19F4_8DnGn36tjGuS8Otfsg5QRDTXQyJTfQpGrc697HsAMiTlv6aKKH1x9rd8RYffluI7amPUvCAFOLDPlcH0Wmq3b0eiCJGUFi5xLhqp7E0CSt0hTFYxB6dY2H6Wzh7sCcBey93TbwJFArhcbar6U-Owd5QCsUUS-eW3OPMN5OPmYACwRJ0AJHESsjVTmsnfCw6EkMCUQlXmzz8Q2TMF8v1PHPv5185Z04w14rDY78E1UjdDOJO7W7jBK79JetWj5wUCOttBGolj_G7T9_9j0V5sA0dRn88wib19BIjboDHOczufyCv78x1f4njGMZZFwb"
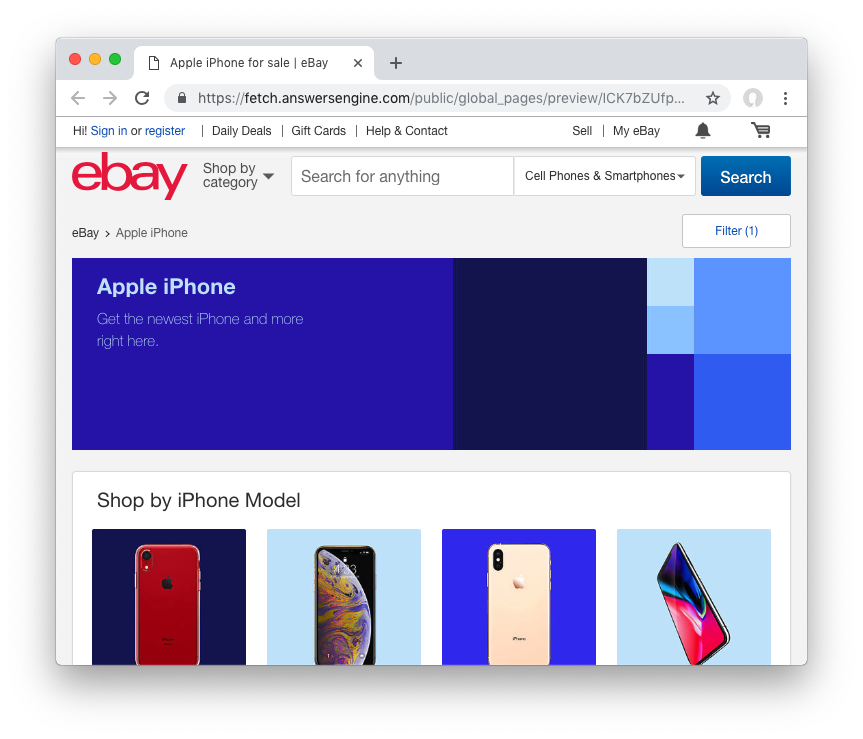
Copy and paste the link that you got from the command line result, into a browser, and you will see the actual content of the the cache.
Previewing the cached page is a powerful thing when developing a parser script, because it allows you to get the actual page that the parser will execute on. This is much better than other kinds of web scraping frameworks out there, where you are developing scraper codes and “hoping” that the page scraped will be the same with what you are seeing.
Once you have the previewed content opened on your browser, let’s look at it, and try to extract the listing names. You can use the Chrome Developer Tool (or other similar tools) to extract the DOM path.
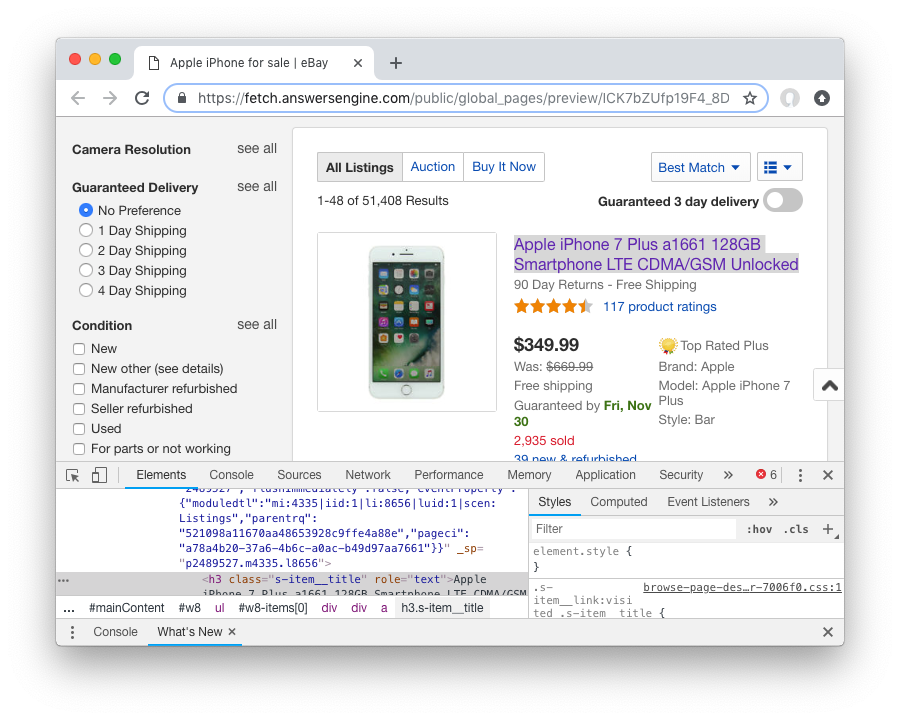
What we are going to do next is to create a ruby script for parsing and extracting the listing names, prices, and the listing URLs, and enqueue additional pages, that we can parse on a later step.
Let’s now create a ruby file, called listings.rb. For standard conventions, let’s put this file in a directory called ‘parsers.’
$ mkdir parsers
$ touch parsers/listings.rb
$ ls -alth
total 8
drwxr-xr-x 14 johndoe staff 448B 27 Nov 20:01 .git
drwxr-xr-x 3 johndoe staff 96B 27 Nov 20:01 parsers
drwxr-xr-x 6 johndoe staff 192B 27 Nov 20:01 .
-rw-r--r-- 1 johndoe staff 123B 26 Nov 16:54 config.yaml
drwxr-xr-x 3 johndoe staff 96B 26 Nov 16:15 seeder
drwxr-xr-x 10 johndoe staff 320B 26 Nov 15:59 ..
$ ls -alth parsers
total 0
drwxr-xr-x 3 johndoe staff 96B 27 Nov 20:01 .
-rw-r--r-- 1 johndoe staff 0B 27 Nov 20:01 listings.rb
drwxr-xr-x 6 johndoe staff 192B 27 Nov 20:01 ..
Next, type the following codes into the parsers/listings.rb file.
nokogiri = Nokogiri.HTML(content)
“content” is a reserved word that contains the content data. In this case, it is the same exact html content that you are currently also previewing from the globalpage. We support the use Nokogiri for parsing html/xml.
Let’s add the codes that loops through the listing rows and extract each individual listing name, price, and listings URLs.
Get the group of listings from nokogiri.
listings = nokogiri.css('ul.b-list__items_nofooter li.s-item')
And then loop through the listing rows to extract the name, price, listing URL, and save the records to a Fetch collection.
listings.each do |listing|
# initialize an empty hash
product = {}
# extract the information into the product hash
product['title'] = listing.at_css('h3.s-item__title')&.text
# extract the price
product['price'] = listing.at_css('.s-item__price')&.text
# extract the listing URL
item_link = listing.at_css('a.s-item__link')
product['url'] = item_link['href'] unless item_link.nil?
# specify the collection where this record will be stored
product['_collection'] = "listings"
# save the product to the job’s outputs
outputs << product
end
“outputs” is a reserved word, that contains a list of records that will be stored onto the scrape job’s output collection(s)
Once you’ve written the codes, your listings.rb script should look like this:
# initialize nokogiri
nokogiri = Nokogiri.HTML(content)
# get the group of listings
listings = nokogiri.css('ul.b-list__items_nofooter li.s-item')
# loop through the listings
listings.each do |listing|
# initialize an empty hash
product = {}
# extract the information into the product hash
product['title'] = listing.at_css('h3.s-item__title')&.text
# extract the price
product['price'] = listing.at_css('.s-item__price')&.text
# extract the listing URL
item_link = listing.at_css('a.s-item__link')
product['url'] = item_link['href'] unless item_link.nil?
# specify the collection where this record will be stored
product['_collection'] = "listings"
# save the product to the job’s outputs
outputs << product
end
Now that you’ve created the listings.rb file, let’s do a trial-run of this page to ensure that this page would execute properly on Fetch.
Let’s use the parser try command on this script on the same GID.
$ answersengine parser try ebay parsers/listings.rb www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e
Trying parser script
getting Job Page
=========== Parsing Executed ===========
----------- Outputs: -----------
[
{
"title": "Apple iPhone 7 Plus a1661 128GB Smartphone LTE CDMA/GSM Unlocked",
"price": "$349.99",
"url": "https://www.ebay.com/itm/Apple-iPhone-7-Plus-a1661-128GB-Smartphone-LTE-CDMA-GSM-Unlocked/201795245944?epid=232746597&hash=item2efbef1778:m:mks-K6wL_LJV1VV0f3-E8ow:sc:USPSPriority!95113!US!-1&var=501834147259",
"_collection": "listings"
},
{
"title": "Apple iPhone XS MAX 256GB - All Colors - GSM & CDMA UNLOCKED",
"price": "$1,199.00",
"url": "https://www.ebay.com/itm/Apple-iPhone-XS-MAX-256GB-All-Colors-GSM-CDMA-UNLOCKED/163267140481?epid=24023697465&hash=item26037adb81:m:m63pSpGuBZVZTiz-IS3A-UA:sc:USPSPriorityMailPaddedFlatRateEnvelope!95113!US!-1&var=462501487846",
"_collection": "listings"
},
...
In the trial-run above, you saw that we were able to extract into several outputs correctly.
Seems like this is a successful trial run.
Let’s now commit this code to Git.
$ git add .
$ git commit -m 'added listings parser'
[master e1a8980] added listings parser
1 file changed, 27 insertions(+)
create mode 100644 parsers/listings.rb
Now that we’re done with creating the parser script, there is only one thing left to do before this is ready to be run on Fetch. And that is to modify the config file so that it contains the references pointing to this file.
Add the parsers section of the config.yaml so that it looks like the following:
seeder:
file: ./seeder/seeder.rb
disabled: false # Optional. Set it to true if you want to disable
parsers:
- page_type: listings
file: ./parsers/listings.rb
disabled: false # Optional
And let’s commit this to Git, and push it to your remote Git repository.
$ git add .
$ git commit -m 'add listings parser to config'
[master 209dba3] add listings parser to config
1 file changed, 6 insertions(+), 2 deletions(-)
$ git push origin master
Counting objects: 7, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (7/7), 1.12 KiB | 1.12 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0)
To https://github.com/answersengine/ebay-scraper.git
c32d451..209dba3 master -> master
Now that you’ve pushed the code to your remote Git repository, let’s deploy the scraper again.
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
"id": 130,
"scraper_id": 20,
"commit_hash": "209dba31698b2146b9c841f0a91bfdd966f973aa",
"git_repository": "https://github.com/answersengine/ebay-scraper.git",
"git_branch": "master",
"errors": null,
"success": true,
"created_at": "2018-11-28T03:05:02.220272Z",
"config": {
"parsers": [
{
"file": "./parsers/listings.rb",
"page_type": "listings"
}
],
"seeder": {
"file": "./seeder/seeder.rb"
}
}
}
Looks like a successful deploy.
Because you have a running scrape job (you’ve started this scrape job in Exercise 2), as soon as you deploy new code, the scrape job will immediately download and execute.
Let’s now check for the stats on this job.
$ answersengine scraper stats ebay
{
"job_id": 70,
"pages": 1,
"fetched_pages": 1,
"to_fetch": 0,
"fetching_failed": 0,
"fetched_from_web": 1,
"fetched_from_cache": 0,
"parsed_pages": 1, # Parsed pages is now 1
"to_parse": 0,
"parsing_failed": 0,
"outputs": 48, # We now have 48 output records
"output_collections": 1, # And we have 1 output collection
"workers": 1,
"time_stamp": "2018-11-28T03:06:04.959513Z"
}
If you look at the result of the command above, you see that our scraper has already parsed the listings page, and created 48 output records, and it also created one output collection.
Let’s check the scraper log to see if there are any errors:
$ answersengine scraper log ebay
Seems like there are no errors so far.
Let’s look further on what collections are created by the scraper.
$ answersengine scraper output collections ebay
[
{
"collection": "listings",
"count": 48
}
]
Just as we specified in the parser code, it saves the output records onto the listings collection.
Let’s look at the output records inside the listings collection.
$ answersengine scraper output list ebay --collection listings
[
{
"_collection": "listings",
"_created_at": "2018-11-28T03:05:56.510638Z",
"_gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"_id": "016f6ca8010541539e13c687edd6cf91",
"_job_id": 70,
"price": "$239.99 to $339.99",
"title": "Apple iPhone 7 32/128/256GB Factory Unlocked AT\u0026T Sprint Verizon T-Mobile",
"url": "https://www.ebay.com/itm/Apple-iPhone-7-32-128-256GB-Factory-Unlocked-AT-T-Sprint-Verizon-T-Mobile/382231636268?epid=232669182\u0026hash=item58fec7e92c:m:mGdfdcg2f2rqhQh7_Aq4EYQ\u0026var=651061946000"
},
{
"_collection": "listings",
"_created_at": "2018-11-28T03:05:56.510638Z",
"_gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"_id": "029788f01c73460683f0910681348222",
"_job_id": 70,
"price": "$374.99",
"title": "Apple iPhone 7 Plus a1661 256GB Smartphone LTE CDMA/GSM Unlocked",
"url": "https://www.ebay.com/itm/Apple-iPhone-7-Plus-a1661-256GB-Smartphone-LTE-CDMA-GSM-Unlocked/152410916266?epid=238409027\u0026hash=item237c6605aa:m:mks-K6wL_LJV1VV0f3-E8ow:sc:USPSPriority!95113!US!-1\u0026var=451703657817"
},
...
We’ve got almost same exact output records with the ones on the trial-run. The difference is, now you can see “_gid”, “_created_at”, “_id”, and “_job_id”. These are metadatas that are automatically generated. Output metadata fields are usually starts with “_”(underscore) on their field names.
If you want to see one output record, you can run the following:
$ answersengine scraper output show ebay 97d7bcd021de4bdbb6818825703b26dd --collection listings
{
"_collection": "listings",
"_created_at": "2018-11-28T03:05:56.510638Z",
"_gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"_id": "97d7bcd021de4bdbb6818825703b26dd",
"_job_id": 70,
"price": "$259.99 to $344.99",
"title": "Apple iPhone 7 - 32/128/256GB Unlocked GSM (AT\u0026T T-Mobile +More) 4G Smartphone",
"url": "https://www.ebay.com/itm/Apple-iPhone-7-32-128-256GB-Unlocked-GSM-AT-T-T-Mobile-More-4G-Smartphone/142631642365?epid=240455139\u0026hash=item21358224fd:m:miu7oWIlKlIyiHYnR76rFnA\u0026var=441608064608"
}
We’re nearing the end of the exercise. Let’s cancel the current scrape job, as we will be creating a new job in the next exercise.
$ answersengine scraper job cancel ebay
{
"id": 70,
"scraper_name": "ebay",
"scraper_id": 20,
"created_at": "2018-11-26T22:06:54.399547Z",
"freshness": null,
"force_fetch": false,
"status": "cancelled",
"seeding_at": "2018-11-26T22:07:10.68643Z",
"seeding_failed_at": null,
"seeded_at": "2018-11-26T22:07:49.021679Z",
"seeding_try_count": 1,
"seeding_fail_count": 0,
"seeding_error_count": 0,
"worker_count": 1
}
Congratulations, you have completed exercise 3. You have learned to create a parser script that extracts a web page and save it to the Fetch output, and you have also learned how to use some useful commands related to scraper outputs and their collections.
The source codes that we’ve built throughout the exercise are located here https://github.com/answersengine/ebay-scraper/tree/exercise3.
In the next exercise, we’ll be building upon this exercise to enqueue more pages to be scraped.
Exercise 4: Enqueue more pages, and pass variables to the next pages¶
In the last exercise, You have learned to create a parser script that extracts a web page and save it to the Fetch output, and you have also learned how to use some useful commands related to scraper outputs and their collections.
If you’ve skipped the last exercise, you can see the source code here: https://github.com/answersengine/ebay-scraper/tree/exercise4.
In this exercise, we will be building upon the previous exercise by enqueuing more pages from the listings parser, onto the details pages. We’ll also be passing some page variables that we generated on the listings parser onto the the detail pages, so that the parser for the detail page can take advantage of it.
Let’s add the following code inside the listings loop, just before the end of the loop in parsers/listings.rb:
# enqueue more pages to the scrape job
pages << {
url: product['url'],
page_type: 'details',
vars: {
title: product['title'],
price: product['price']
}
}
Once done, the parsers/listings.rb should look like this:
# initialize nokogiri
nokogiri = Nokogiri.HTML(content)
# get the group of listings
listings = nokogiri.css('ul.b-list__items_nofooter li.s-item')
# loop through the listings
listings.each do |listing|
# initialize an empty hash
product = {}
# extract the information into the product hash
product['title'] = listing.at_css('h3.s-item__title')&.text
# extract the price
product['price'] = listing.at_css('.s-item__price')&.text
# extract the listing URL
item_link = listing.at_css('a.s-item__link')
product['url'] = item_link['href'] unless item_link.nil?
# specify the collection where this record will be stored
product['_collection'] = "listings"
# save the product to the outputs.
outputs << product
# enqueue more pages to the scrape job
pages << {
url: product['url'],
page_type: 'details',
vars: { # adding vars to this page
title: product['title'],
price: product['price']
}
}
end
Let’s now trial-run this page on a GID of the page that we’ve used on the past exercise.
$ answersengine parser try ebay parsers/listings.rb www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e
Trying parser script
getting Job Page
=========== Parsing Executed ===========
----------- Outputs: -----------
[
{
"title": "Apple iPhone 7 Plus a1661 128GB Smartphone LTE CDMA/GSM Unlocked",
"price": "$349.99",
"url": "https://www.ebay.com/itm/Apple-iPhone-7-Plus-a1661-128GB-Smartphone-LTE-CDMA-GSM-Unlocked/201795245944?epid=232746597&hash=item2efbef1778:m:mks-K6wL_LJV1VV0f3-E8ow:sc:USPSPriority!95113!US!-1&var=501834147259",
"_collection": "listings"
},
...
----------- New Pages to Enqueue: -----------
[
{
"url": "https://www.ebay.com/itm/Apple-iPhone-7-Plus-a1661-128GB-Smartphone-LTE-CDMA-GSM-Unlocked/201795245944?epid=232746597&hash=item2efbef1778:m:mks-K6wL_LJV1VV0f3-E8ow:sc:USPSPriority!95113!US!-1&var=501834147259",
"page_type": "details",
"vars": {
"title": "Apple iPhone 7 Plus a1661 128GB Smartphone LTE CDMA/GSM Unlocked",
"price": "$349.99"
}
},
{
"url": "https://www.ebay.com/itm/Apple-iPhone-XS-MAX-256GB-All-Colors-GSM-CDMA-UNLOCKED/163267140481?epid=24023697465&hash=item26037adb81:m:m63pSpGuBZVZTiz-IS3A-UA:sc:USPSPriorityMailPaddedFlatRateEnvelope!95113!US!-1&var=462501487846",
"page_type": "details",
"vars": {
"title": "Apple iPhone XS MAX 256GB - All Colors - GSM & CDMA UNLOCKED",
"price": "$1,199.00"
}
},
...
The trial-run seems to be successful, and you now see a new pages to enqueue, as well as the page vars inside each of them.
Let’s now commit this code and push it to the remote Git repository.
$ git add .
$ git commit -m 'modified listings parser to enqueue more pages'
[master 332e06d] modified listings parser to enqueue more pages
1 file changed, 10 insertions(+)
$ git push origin master
Counting objects: 4, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 567 bytes | 567.00 KiB/s, done.
Total 4 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/answersengine/ebay-scraper.git
209dba3..332e06d master -> master
Now deploy it, and start a new scrape job, so that we have some page contents in the shared cache.
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
"id": 131,
"scraper_id": 20,
"commit_hash": "332e06d01f073ac00840184cd06c826429b3b55c",
...
$ answersengine scraper start ebay
Starting a scrape job...
{
"id": 88,
"scraper_id": 20,
...
Let’s check the scraper stats now:
$ answersengine scraper stats ebay
{
"job_id": 88,
"pages": 49,
"fetched_pages": 3,
"to_fetch": 46,
"fetching_failed": 0,
...
}
Looks like we now have 49 pages in this job. This means we have successfully modified the parsers/listings.rb to enqueue more pages.
Let’s see what pages do we have in this scrape job:
$ answersengine scraper page list ebay
[
{
"gid": "www.ebay.com-eb1b04c3304ff741b5dbd3234c9da75e",
"job_id": 88,
"page_type": "details",
"method": "GET",
"url": "https://www.ebay.com/itm/NEW-Apple-iPhone-6S-16GB-32GB-64GB-128GB-UNLOCKED-Gold-Silver-Gray-GSM/153152283464?epid=240420050\u0026hash=item23a8966348%3Am%3AmN52WSYRFZEr3HNCPAgfZfQ\u0026var=453004437286",
...
"vars": {
"price": "$275.99",
"title": "Apple iPhone 7 128GB 4.7\" Retina Display 4G GSM BLACK UNLOCKED Smartphone SRF"
},
...
Looks like it correctly enqueued the page and the vars.
Now, let’s preview the content of the GID from the above result.
$ answersengine globalpage content www.ebay.com-eb1b04c3304ff741b5dbd3234c9da75e
Preview content url: "https://fetch.answersengine.com/public/global_pages/preview/V58Ts9JDocg7qyjT5cxkIL5Dk_UEuEyOQXaHbxBdNJiHmsP2nhE17a8gzwXO8RYUNJ2X1K7PWh0ziIXO7ORylLVLppiufL1edZChFFr8quZuivTJql7B3z_btQA9p1wQqiowc4U90VZtP4bOrShW9v9fA6V4vedfpJL9TM5G8QR-zYhUbrwAIpB4WDLALpPz19ZPZ1rjt8OVYJ2GRDCgr2fPb1S2uBKMI35k1oXO3Cr0yf8St_M5lZqUbEYyqVLPCwDC7ZFk1J_KxQvzgD6vWqmKRoGk1XVS7gxPBusNip47gANzPbo9p3wjWHjqaQhhPb0UFXKBithJ"
Now, let’s create a details parser and extract the seller’s username and their feedback.
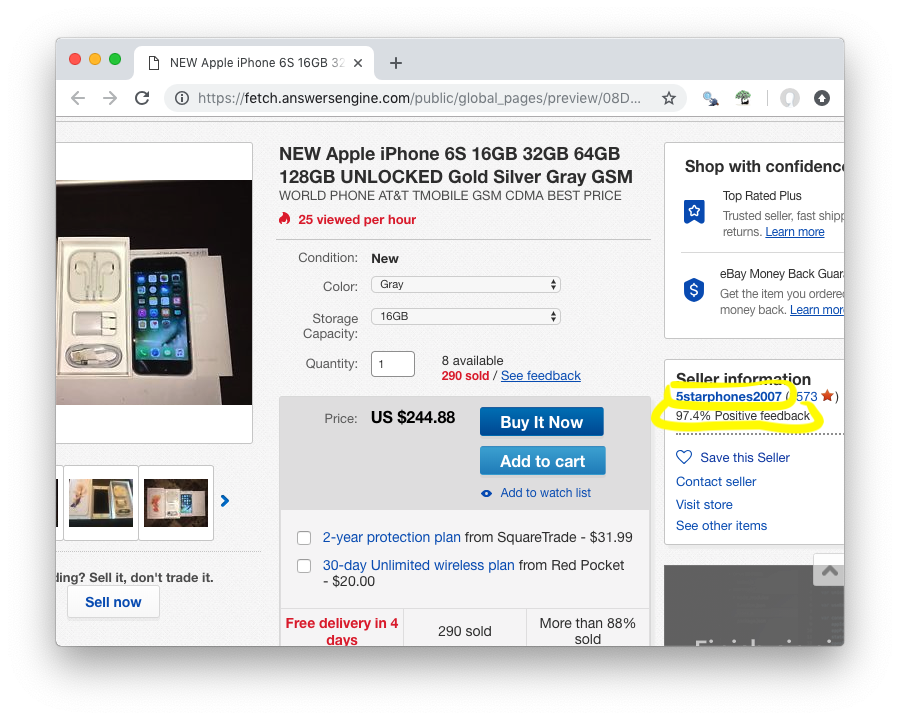
Create the parsers/details.rb file and Insert the following code:
# initialize nokogiri
nokogiri = Nokogiri.HTML(content)
# get the seller username
seller = nokogiri.at_css('.si-inner .mbg-nw')&.text
# get the seller's feedback
feedback = nokogiri.at_css('.si-inner #si-fb')&.text
# save it into outputs
outputs << {
_collection: 'products',
title: page['vars']['title'],
price: page['vars']['price'],
seller: seller,
feedback: feedback
}
Let’s now give this parser a try on one of the details page:
$ answersengine parser try ebay parsers/details.rb www.ebay.com-eb1b04c3304ff741b5dbd3234c9da75e
Trying parser script
getting Job Page
=========== Parsing Executed ===========
----------- Outputs: -----------
[
{
"_collection": "products",
"title": "Apple iPhone 8 Plus a1897 64GB Smartphone GSM Unlocked",
"price": "$550.99 to $599.99",
"seller": "mywit",
"feedback": "97.6% Positive feedback"
}
]
This trial-run looks really good. That we’re able to extract the details page without error, and assumed that we would be able to save the output to the products collection.
Let’s now commit this details parser.
$ git add .
$ git commit -m 'added details parser'
[master 59bab08] added details parser
1 file changed, 17 insertions(+)
create mode 100644 parsers/details.rb
Let’s not forget to update the config yaml file so that it points to this parser file. The config file should look like this now:
seeder:
file: ./seeder/seeder.rb
disabled: false
parsers:
- page_type: listings
file: ./parsers/listings.rb
disabled: false
- page_type: details
file: ./parsers/details.rb
disabled: false
Let’s commit the file, and push it to the remote Git repository.
$ git add .
$ git commit -m 'added details parser config'
[master 97dac60] added details parser config
1 file changed, 4 insertions(+), 1 deletion(-)
$ git push origin master
Counting objects: 7, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (7/7), done.
Writing objects: 100% (7/7), 1008 bytes | 1008.00 KiB/s, done.
Total 7 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/answersengine/ebay-scraper.git
332e06d..97dac60 master -> master
Next, let’s deploy it to Fetch. Since we already have the current job running, we don’t need to do anything else, and the scraper will immediately execute the newly deployed code.
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
"id": 132,
"scraper_id": 20,
"commit_hash": "97dac606b24a8c818f3234419cb9180999bc9d71",
"git_repository": "https://github.com/answersengine/ebay-scraper.git",
"git_branch": "master",
"errors": null,
"success": true,
"created_at": "2018-11-28T06:05:48.866609Z",
"config": {
"parsers": [
{
"file": "./parsers/listings.rb",
"page_type": "listings"
},
{
"file": "./parsers/details.rb",
"page_type": "details"
}
],
"seeder": {
"file": "./seeder/seeder.rb"
}
}
}
Let’s check to see the scraper stats:
$ answersengine scraper stats ebay
{
...
"parsed_pages": 49,
"to_parse": 0,
"parsing_failed": 0,
"outputs": 96,
"output_collections": 2,
...
}
This looks good, as it shows that there are 2 collections, and a total of 96 output records.
Let’s also check the scraper log to see if there are any errors:
$ answersengine scraper log ebay
Seems like there are no errors so far.
Let’s look to see if the products collection has been correctly created:
$ answersengine scraper output collection ebay
[
{
"collection": "listings",
"count": 48
},
{
"collection": "products",
"count": 48
}
]
Looks good. Now, let’s look inside the products collection and see if the outputs are correctly saved:
$ answersengine scraper output list ebay --collection products
[
{
"_collection": "products",
"_created_at": "2018-11-28T06:15:13.061168Z",
"_gid": "www.ebay.com-82d133d0dba1255c7424f99ab79776e9",
"_id": "ac3c99ab8d3846a98d3317660259db06",
"_job_id": 91,
"feedback": "99.8% Positive feedback",
"price": "$269.98",
"seller": "overdrive_brands",
"title": "Apple iPhone 7 32GB Smartphone AT\u0026T T-Mobile Unlocked 4G LTE Black Red Rose Gold"
},
{
"_collection": "products",
"_created_at": "2018-11-28T06:15:13.47726Z",
"_gid": "www.ebay.com-0cc7480bd6afecb10cf81bdc5904ea74",
"_id": "7be4ee3e544e4e5db9115215572259b9",
"_job_id": 91,
"feedback": "99.9% Positive feedback",
"price": "$569.00",
"seller": "alldayzip",
"title": "Apple iPhone 8 64GB RED \u0026 All Colors! GSM \u0026 CDMA UNLOCKED!! BRAND NEW! Warranty!"
},
...
The output looks wonderful.
Congratulations, you have completed exercise 4. You have learned to enqueue more pages from the listings parser onto detail pages. You have also learned about passing some page variables that were generated on the listings parser onto the the detail pages. The details parsers then combined the data from the page vars and the extracted data from the details page, into the “products” output collection.
The source codes that we’ve built throughout the exercise are located here https://github.com/answersengine/ebay-scraper/tree/exercise4.
In the next exercise, you will be learning how to export output by creating Exporters.
Exercise 5: Exporting outputs¶
In the last exercise, You have learned to do some more advanced techniques of creating parsers, and also saved the records into the output collection.
If you’ve skipped the last exercise, you can see the source code here: https://github.com/answersengine/ebay-scraper/tree/exercise4.
In this exercise, we will be exporting outputs by creating Exporters. In Fetch, an Exporter is a set of configurations that allows you to Export something. We have several different kinds of Exporters. Please read the documentation for further details
We’re going to export the products collection ( which you’ve created in Exercise 4) into a JSON file that we can download, once the export process has finished.
Before exporting all the outputs of the products collection, it is a good idea to sample a smaller number of records first, to make sure the outputs are looking good.
To do that, let’s create an exporter configuration file, called products_last10_json.yaml. For standard conventions, let’s put this file in a directory called ‘exporters’.
First you need to create the exporters directory on the project root directory.
$ mkdir exporters
$ touch exporters/products_last10_json.yaml
$ ls -alth exporters
total 0
drwxr-xr-x 3 johndoe staff 96B 13 Jan 00:56 .
-rw-r--r-- 1 johndoe staff 0B 13 Jan 00:56 products_last10_json.yaml
drwxr-xr-x 7 johndoe staff 224B 13 Jan 00:55 ..
Next let’s put the following content into the products_last10_json.yaml file:
exporter_name: products_last10_json # Must be unique
exporter_type: json
collection: products
write_mode: pretty_array # can be `line`,`pretty`, `pretty_array`, or `array`
limit: 10 # limits to how many records to export
offset: 0 # offset to where the exported record will start from
The above exporter means, we want to export only the last 10 outputs from the products collection
Next, let’s modify the config.yaml file, so that it knows the location of the exporter file.
Your config.yaml should now look like the following:
seeder:
file: ./seeder/seeder.rb
disabled: false
parsers:
- page_type: listings
file: ./parsers/listings.rb
disabled: false
- page_type: details
file: ./parsers/details.rb
disabled: false
# add the following lines below...
exporters:
- file: ./exporters/products_last10_json.yaml
disabled: false
Now, let’s commit these files and push this to the remote repository.
$ git add .
$ git commit -m 'added products_last10_json.yaml exporter'
[master ab7ab52] added products_last10_json.yaml exporter
2 files changed, 10 insertions(+)
create mode 100644 exporters/products_last10_json.yaml
$ git push origin master
Counting objects: 5, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 742 bytes | 742.00 KiB/s, done.
Total 5 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/answersengine/ebay-scraper.git
7bd6091..ab7ab52 master -> master
Let’s now deploy the scraper.
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
"id": 737,
"scraper_id": 20,
...
"config": {
"exporters": [
{
"collection": "products",
"exporter_name": "products_last10_json",
"exporter_type": "json",
"limit": 10,
"offset": 0,
"write_mode": "pretty_array"
}
],
...
}
You’ve now deployed the newest code.
To make sure that the exporters are deployed correctly, you can check a list of available exporters on this scraper:
$ answersengine scraper exporter list ebay
[
{
"collection": "products",
"exporter_name": "products_last10_json",
"exporter_type": "json",
"limit": 10,
"offset": 0,
"write_mode": "pretty_array"
}
]
Next, let’s start the exporter:
$ answersengine scraper exporter start ebay products_last10_json
{
"id": "c700cb749f4e45eeb53609927e21da56", # Export ID here
"job_id": 852,
"scraper_id": 20,
"exporter_name": "products_last10_json",
"exporter_type": "json",
"config": {
"collection": "products",
"exporter_name": "products_last10_json",
"exporter_type": "json",
"limit": 10,
"offset": 0,
"write_mode": "pretty_array"
},
"status": "enqueued", # the status of the export
"created_at": "2019-01-13T06:19:56.815979Z"
}
When you start an exporter, it creates an export record like the above.
You can check the status of the export by specifying the export ID, in this case: c700cb749f4e45eeb53609927e21da56
Let’s now check the status of the export:
$ answersengine scraper export show c700cb749f4e45eeb53609927e21da56
{
"id": "c700cb749f4e45eeb53609927e21da56",
...
"status": "done", # the export is done
"created_at": "2019-01-13T06:19:56.815979Z",
"progress": 100, # Progress is at 100%, again, it means it is done.
"exported_records": 10,
"to_export": 10,
"exporting_at": "2019-01-13T06:19:59.794454Z",
"exported_at": "2019-01-13T06:20:01.125188Z",
"file_name": "c700cb749f4e45eeb53609927e21da56.tgz"
}
As you can see above by looking at the status, it is done. It also shows the export’s file_name: c700cb749f4e45eeb53609927e21da56.tgz
Let’s now download the export, by specifying the export ID, like so:
$ answersengine scraper export download c700cb749f4e45eeb53609927e21da56
Download url: "https://f002.backblazeb2.com/file/exports-fetch-answersengine/c700cb749f4e45eeb53609927e21da56.tgz?Authorization=blablabla"
You’re now seeing the download URL, which allows you to copy and paste into your browser so that you’ll download the actual file.
If you uncompress this .tgz file, you’ll see the following directory with one content:

And when you open the json file, you’ll see the following content with the 10 most recent records from the products collection:
[{
"_collection": "products",
"_created_at": "2019-01-13T01:17:21.925076Z",
"_gid": "www.ebay.com-384cfde09349adaa48f78c44b5f840db",
"_id": "574d346fb77c4d669896f15f6b40f169",
"_job_id": 852,
"feedback": "97.6% Positive feedback",
"price": "$183.99 to $235.99",
"seller": "x-channel",
"title": "New *UNOPENDED* Apple iPhone SE - 16/64GB 4.0\" Unlocked Smartphone"
},
{
"_collection": "products",
"_created_at": "2019-01-13T01:16:53.494641Z",
"_gid": "www.ebay.com-e5681a88f980aa906f7c4414e9120685",
"_id": "231034ec579c4b329b0eaf8ebc642ed1",
"_job_id": 852,
"feedback": "98.3% Positive feedback",
"price": "$299.99",
"seller": "bidallies",
"title": "Apple iPhone 7 Plus 32GB Factory Unlocked 4G LTE iOS WiFi Smartphone"
},
]
Now that this file looks good, let’s create another exporter to export the all of records.
This is a very simple process, you just need to create another exporter file called products_json.yaml with the following content:
exporter_name: products_json
exporter_type: json
collection: products
Notice how we’re not putting anything such as limit, offset, and even write_mode. This is because the default value for write_mode is pretty_array.
Don’t forget to update the config.yaml file to look like the following:
seeder:
file: ./seeder/seeder.rb
disabled: false
parsers:
- page_type: listings
file: ./parsers/listings.rb
disabled: false
- page_type: details
file: ./parsers/details.rb
disabled: false
exporters:
- file: ./exporters/products_last10_json.yaml
disabled: false
# Add the following lines below...
- file: ./exporters/products_json.yaml
disabled: false
Let’s now commit and push this to the remote repos:
$ git add .
$ git commit -m 'added full products exporter'
[master 2f453eb] added full products exporter
2 files changed, 5 insertions(+)
create mode 100644 exporters/products_json.yaml
$ git push origin master
Counting objects: 5, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 569 bytes | 569.00 KiB/s, done.
Total 5 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/answersengine/ebay-scraper.git
ab7ab52..2f453eb master -> master
Let’s now deploy it:
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
...
"config": {
"exporters": [
{
"collection": "products",
"exporter_name": "products_last10_json",
"exporter_type": "json",
"limit": 10,
"offset": 0,
"write_mode": "pretty_array"
},
{
"collection": "products",
"exporter_name": "products_json",
"exporter_type": "json",
"limit": null,
"offset": null
}
],
...
}
Once deployed, let’s see what exporters are available to be used on the scraper:
$ answersengine scraper exporter list ebay
[
{
"collection": "products",
"exporter_name": "products_last10_json",
"exporter_type": "json",
"limit": 10,
"offset": 0,
"write_mode": "pretty_array"
},
{
"collection": "products",
"exporter_name": "products_json",
"exporter_type": "json",
"limit": null,
"offset": null
}
]
Great, we’ve verified that we have indeed two exporters.
Now, start the exporter that we’ve just recently created:
$ answersengine scraper exporter start ebay products_json
{
"id": "6bfd70f5c9f346b3a623cab50ea8a84c",
"job_id": 852,
"scraper_id": 20,
"exporter_name": "products_json",
"exporter_type": "json",
"config": {
"collection": "products",
"exporter_name": "products_json",
"exporter_type": "json",
"limit": null,
"offset": null
},
"status": "enqueued",
"created_at": "2019-01-13T06:53:30.698121Z"
}
Next, let’s check the status of the export, by specifying the export ID:
$ answersengine scraper export show 6bfd70f5c9f346b3a623cab50ea8a84c
{
"id": "6bfd70f5c9f346b3a623cab50ea8a84c",
"job_id": 852,
"scraper_id": 20,
"scraper_name": "ebay",
"exporter_name": "products_json",
"exporter_type": "json",
"config": {
"collection": "products",
"exporter_name": "products_json",
"exporter_type": "json",
"limit": null,
"offset": null
},
"status": "done",
"created_at": "2019-01-13T06:53:30.698121Z",
"progress": 100,
"exported_records": 48,
"to_export": 48,
"exporting_at": "2019-01-13T06:53:33.501493Z",
"exported_at": "2019-01-13T06:53:35.141981Z",
"file_name": "6bfd70f5c9f346b3a623cab50ea8a84c.tgz"
}
As you can see, the status is now done. Next, let’s download the export:
$ answersengine scraper export download 6bfd70f5c9f346b3a623cab50ea8a84c
Download url: "https://f002.backblazeb2.com/file/exports-fetch-answersengine/6bfd70f5c9f346b3a623cab50ea8a84c.tgz?Authorization=blablabla"
Now, if you open and count the records inside the file, you will notice that it will have 48 records. Which is the exact same count that is shown in the products collection below:
$ answersengine scraper output collection ebay
[
{
"collection": "listings",
"count": 48
},
{
"collection": "products",
"count": 48 # the exported count is the same as this
}
]
You have now created and used two exporters successfully.
Let’s try to use a different kind of exporter. This time, let’s use the CSV Exporter. Create another file, called products_csv.yaml with the following content:
exporter_name: products_csv
exporter_type: csv
collection: products
fields:
- header: "gid"
path: "_gid"
- header: "created_at"
path: "_created_at"
- header: "title"
path: "title"
- header: "price"
path: "price"
- header: "feedback"
path: "feedback"
- header: "seller"
path: "seller"
Since you’ve done this a couple of times now, go ahead and commit and deploy this exporter by yourself. Don’t forget to add the path to this file, into your config.yaml file.
We’re nearing the end of the exercise, but before that, I want to show you two more things.
First, Fetch allows you to automatically run the exporter when the scrape job is done.
To do this, simply add start_on_job_done: true to your exporter configuration.
Let’s update the file products_csv.yaml so that it looks like following content:
exporter_name: products_csv
exporter_type: csv
collection: products
start_on_job_done: true # we added this field
fields:
- header: "gid"
path: "_gid"
- header: "created_at"
path: "_created_at"
- header: "title"
path: "title"
- header: "price"
path: "price"
- header: "feedback"
path: "feedback"
- header: "seller"
path: "seller"
Now that you’ve done the above, whenever your scrape job is done, the products_csv exporter will automatically be run.
Last thing to show before you go. Let’s look at a list of all the exports that were exported from all scrapers in your account:
$ answersengine scraper export list
[
{
"id": "fe70e697354643429712c9880fb3678e",
...
},
{
"id": "c700cb749f4e45eeb53609927e21da56",
...
},
...
You can even filter all the exports based on the scraper name:
$ answersengine scraper export list --scraper-name ebay
[
{
"id": "6bfd70f5c9f346b3a623cab50ea8a84c",
...
},
...
Congratulations, you have completed exercise 5.
You have learned how to create an exporter that can export partial records, as well as an exporter that exports the full records.
Fetch offers several kinds of exporters including CSV that exports to the CSV format, and Content exporter that allows you to export contents, such as files, images, pdf, etc. For more information please visit the documentation
The source codes that we’ve built throughout the exercise are located here https://github.com/answersengine/ebay-scraper/tree/exercise5.
Exercise 6: Create a finisher script¶
In the last exercise we went through creating an exporter to export scraper output. In this exercise we are going to take a look at creating a finisher script. A finisher script is a script that runs after a scraper job is done. With a finisher script you can do things like create summaries or run QA on your scraped data. Both of which we will show you how to do. Let’s first create a finisher script to create a summary that shows the total number of listings. Create a folder called finisher in your project root directory and then create a file called finisher.rb inside with the following:
collections = AnswersEngine::Client::ScraperJobOutput.new.collections("ebay")
collection = collections.find{|collection| collection['collection'] == "listings" }
if collection
total = collection["outputs"]
outputs << {
"_collection" => "summary",
"total_listings" => total
}
else
puts "no listings collection found"
end
Basically we are using the AnswersEngine gem to find all the collections for our ebay scraper and selecting the, “listings” collection. We then get the total number of listings inside this collection and save it to a new collection called, “summary.” Next, let’s add our finisher to the config.yaml file so that it looks like the following:
seeder:
file: ./seeder/seeder.rb
disabled: false
parsers:
- page_type: listings
file: ./parsers/listings.rb
disabled: false
- page_type: details
file: ./parsers/details.rb
disabled: false
exporters:
- file: ./exporters/products_last10_json.yaml
disabled: false
- file: ./exporters/products_json.yaml
disabled: false
finisher:
file: ./finisher/finisher.rb
disabled: false
Now that we have updated our config, let’s give this finisher a try by running the following:
answersengine finisher try ebay finisher/finisher.rb
Trying seeder script
=========== Seeding Executed ===========
----------------------------------------
Would have saved 1 out of 1 Outputs
[
{
"_collection": "summary",
"total_listings": 39
}
]
Looks like this worked! The finisher would have saved a summary collection with the total number of listings. Let’s now commit and push this to the remote repos:
$ git add .
$ git commit -m 'added finisher script'
[master 2f453eb] added finisher script
1 files changed, 5 insertions(+)
create mode 100644 finisher/finisher.rb
$ git push origin master
Counting objects: 5, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 569 bytes | 569.00 KiB/s, done.
Total 5 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/answersengine/ebay-scraper.git
ab7ab52..2f453eb master -> master
Let’s now deploy it:
$ answersengine scraper deploy ebay
Deploying scraper. This may take a while...
{
...
"config": {
"finisher": {
"file": "./finisher/finisher.rb"
},
...
}
And then start the scraper.
$ answersengine scraper start ebay
Starting a scrape job...
Give the scraper a few minutes and then check the status. We are looking for the “finisher_status” to be “done.” It should look something like the following:
answersengine scraper stats ebay
{
"scraper_name": "ebay",
"job_id": 10066,
"job_status": "done",
"seeding_status": "done",
"finisher_status": "done",
"pages": 40,
"to_fetch": 0,
"fetching": 0,
"fetching_failed": 0,
"fetching_dequeue_failed": 0,
"to_parse": 0,
"parsing_started": 0,
"parsing": 0,
"parsed": 40,
"parsing_failed": 0,
"parsing_dequeue_failed": 0,
"limbo": 0,
"fetched": 40,
"fetched_from_web": 0,
"fetched_from_cache": 40,
"outputs": 79,
"output_collections": 0,
"standard_workers": 1,
"browser_workers": 0,
"time_stamp": "2019-08-15T17:32:48.771103Z"
}
Once the finisher has run we can check our collections with the following:
answersengine scraper output collections ebay
[
{
"job_id": 10066,
"collection": "listings",
"outputs": 39
},
{
"job_id": 10066,
"collection": "products",
"outputs": 39
},
{
"job_id": 10066,
"collection": "summary",
"outputs": 1
}
]
Looks like our finisher script worked! We now have a summary collection which shows the number of listings.
Next let’s take a look at adding some QA to our finisher so we can validate the scraper results. We will use the ‘ae_easy-qa’ Gem which is a Ruby Gem that allows for doing QA on AnswersEngine script outputs. First, create a file called Gemfile in the project root directory with the following:
gem 'ae_easy-qa'
After creating this file, run the following command in the project root directory:
bundle
This will install the ‘ae_easy-qa’ Gem. You should see something like the following output.
Resolving dependencies...
Using ae_easy-qa 0.0.26
Using bundler 1.17.3
Bundle complete! 1 Gemfile dependency, 2 gems now installed.
Now we need to create a file called ae_easy.yaml, also in the project root directory, with the following:
qa:
individual_validations:
url:
required: true
type: Url
title:
required: true
type: String
This ae_easy.yaml file is where we can define validations for the ‘ae_easy-qa’ Gem to use. In this example, we are going to do validation on the listings collection output. Specifically, we are validating that the “url” field is present and is of type “Url” and that the “title” field is present and is a String.
Next, we just need to add some code to make the validator run in our finisher script. Update the finisher.rb file so it looks like the following:
require "ae_easy/qa'
collections = AnswersEngine::Client::ScraperJobOutput.new.collections("ebay")
collection = collections.find{|collection| collection['collection'] == "listings" }
if collection
total = collection["outputs"]
outputs << {
"_collection" => "summary",
"total_listings" => total
}
else
puts "no listings collection found"
end
vars = { "scraper_name" => "ebay", "collections" => ["listings"]}
AeEasy::Qa::Validator.new.validate_internal(vars, outputs)
We are adding a line that loads the “ae_easy-qa” Gem using require and then doing validation on the listings collection of our ebay scraper. Let’s try our finisher again. Run the following:
answersengine finisher try ebay finisher/finisher.rb
Trying finisher script
1
2
validating scraper: ebay
Validating collection: listings
data count 39
=========== Finisher Executed ===========
----------------------------------------
Would have saved 2 out of 2 Outputs
[
{
"_collection": "summary",
"total_listings": 39
},
{
"pass": "true",
"_collection": "ebay_listings_summary",
"total_items": 39
}
]
Ok, great! The “pass”: “true” means that the validations all passed. Feel free to edit validation rules in the ae_easy.yaml file. There are more details and rules in the, “How to write a QA script to ingest and parse outputs from multiple scrapers” tutorial in the, “Advanced Tutorials” section.
Let’s now commit this update, push it to master, deploy it, and start the scraper again by running the following commands:
$ git add .
$ git commit -m 'added qa to listings in finisher script'
$ git push origin master
$ answersengine scraper deploy ebay
$ answersengine scraper start ebay
Give the scraper a few minutes to finish. You can check the status with the following:
answersengine scraper stats ebay
Once the “finisher_status” if “done,” we can check the collections again for the QA summary with the following command:
answersengine scraper output collections ebay
[
{
"job_id": 10066,
"collection": "listings",
"outputs": 39
},
{
"job_id": 10066,
"collection": "products",
"outputs": 39
},
{
"job_id": 10066,
"collection": "summary",
"outputs": 1
},
{
"pass": "true",
"collection": "ebay_listings_summary",
"total_items": 39
}
]
Great, it looks like we now have our summary as well as our QA summary present, which means the finisher script has run successfully.